1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129# Module 5: Batch Processing
## 5.1 Introduction
* :movie_camera: 5.1.1 Introduction to Batch Processing
[](https://youtu.be/dcHe5Fl3MF8&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=51)
* :movie_camera: 5.1.2 Introduction to Spark
[](https://youtu.be/FhaqbEOuQ8U&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=52)
## 5.2 Installation
Follow [these instructions](setup/) to install Spark:
* [Windows](setup/windows.md)
* [Linux](setup/linux.md)
* [MacOS](setup/macos.md)
And follow [this](setup/pyspark.md) to run PySpark in Jupyter
* :movie_camera: 5.2.1 (Optional) Installing Spark (Linux)
[](https://youtu.be/hqUbB9c8sKg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=53)
Alternatively, if the setups above don't work, you can run Spark in Google Colab.
> [!NOTE]
> It's advisable to invest some time in setting things up locally rather than immediately jumping into this solution
* [Google Colab Instructions](https://medium.com/gitconnected/launch-spark-on-google-colab-and-connect-to-sparkui-342cad19b304)
* [Google Colab Starter Notebook](https://github.com/aaalexlit/medium_articles/blob/main/Spark_in_Colab.ipynb)
## 5.3 Spark SQL and DataFrames
* :movie_camera: 5.3.1 First Look at Spark/PySpark
[](https://youtu.be/r_Sf6fCB40c&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=54)
* :movie_camera: 5.3.2 Spark Dataframes
[](https://youtu.be/ti3aC1m3rE8&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=55)
* :movie_camera: 5.3.3 (Optional) Preparing Yellow and Green Taxi Data
[](https://youtu.be/CI3P4tAtru4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=56)
Script to prepare the Dataset [download_data.sh](code/download_data.sh)
> [!NOTE]
> The other way to infer the schema (apart from pandas) for the csv files, is to set the `inferSchema` option to `true` while reading the files in Spark.
* :movie_camera: 5.3.4 SQL with Spark
[](https://youtu.be/uAlp2VuZZPY&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=57)
## 5.4 Spark Internals
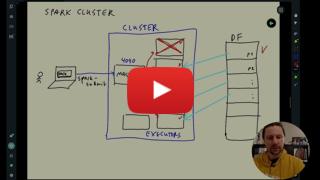
* :movie_camera: 5.4.1 Anatomy of a Spark Cluster
[](https://youtu.be/68CipcZt7ZA&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=58)
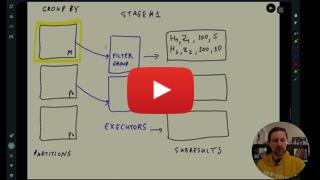
* :movie_camera: 5.4.2 GroupBy in Spark
[](https://youtu.be/9qrDsY_2COo&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=59)
* :movie_camera: 5.4.3 Joins in Spark
[](https://youtu.be/lu7TrqAWuH4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=60)
## 5.5 (Optional) Resilient Distributed Datasets
* :movie_camera: 5.5.1 Operations on Spark RDDs
[](https://youtu.be/Bdu-xIrF3OM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=61)
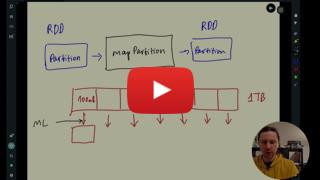
* :movie_camera: 5.5.2 Spark RDD mapPartition
[](https://youtu.be/k3uB2K99roI&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=62)
## 5.6 Running Spark in the Cloud
* :movie_camera: 5.6.1 Connecting to Google Cloud Storage
[](https://youtu.be/Yyz293hBVcQ&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=63)
* :movie_camera: 5.6.2 Creating a Local Spark Cluster
[](https://youtu.be/HXBwSlXo5IA&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=64)
* :movie_camera: 5.6.3 Setting up a Dataproc Cluster
[](https://youtu.be/osAiAYahvh8&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=65)
* :movie_camera: 5.6.4 Connecting Spark to Big Query
[](https://youtu.be/HIm2BOj8C0Q&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=66)
# Homework
* [2026 Homework](../cohorts/2026/05-batch/homework.md)
# Community notes
<details>
<summary>Did you take notes? You can share them here</summary>
* [Notes by Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/5_batch_processing.md)
* [Sandy's DE Learning Blog](https://learningdataengineering540969211.wordpress.com/2022/02/24/week-5-de-zoomcamp-5-2-1-installing-spark-on-linux/)
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week5.md)
* [Alternative : Using docker-compose to launch spark by rafik](https://gist.github.com/rafik-rahoui/f98df941c4ccced9c46e9ccbdef63a03)
* [Marcos Torregrosa's blog (spanish)](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-5-batch-spark)
* [Notes by Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week5)
* [Notes by Oscar Garcia](https://github.com/ozkary/Data-Engineering-Bootcamp/tree/main/Step5-Batch-Processing)
* [Notes by HongWei](https://github.com/hwchua0209/data-engineering-zoomcamp-submission/blob/main/05-batch-processing/README.md)
* [2024 videos transcript](https://drive.google.com/drive/folders/1XMmP4H5AMm1qCfMFxc_hqaPGw31KIVcb?usp=drive_link) by Maria Fisher
* [2025 Notes by Manuel Guerra](https://github.com/ManuelGuerra1987/data-engineering-zoomcamp-notes/blob/main/5_Batch-Processing-Spark/README.md)
* [2025 Notes by Gabi Fonseca](https://github.com/fonsecagabriella/data_engineering/blob/main/05_batch_processing/00_notes.md)
* [2025 Notes on Installing Spark on MacOS (with Anaconda + brew) by Gabi Fonseca](https://github.com/fonsecagabriella/data_engineering/blob/main/05_batch_processing/01_env_setup.md)
* [2025 Notes by Daniel Lachner](https://github.com/mossdet/dlp_data_eng/blob/main/Notes/05_01_Batch_Processing_Spark_GCP.pdf)
* Add your notes here (above this line)
</details>